
תוֹכֶן

מקור: Kran77 / Dreamstime.com
להסיר:
מודלים של למידה עמוקה מלמדים מחשבים לחשוב בעצמם, עם תוצאות מהנות ומעניינות מאוד.
למידה מעמיקה מוחלת על יותר ויותר תחומים ותעשיות. ממכוניות נטולות נהגים, לנגינת גו, להפקת מוזיקת תמונות, ישנם דגמים חדשים למידה עמוקה היוצאים מדי יום. כאן אנו עוברים על מספר מודלים פופולריים של למידה עמוקה. מדענים ומפתחים לוקחים מודלים אלה ומשנים אותם בדרכים חדשות ויצירתיות. אנו מקווים כי חלון הראווה הזה יכול לעודד אותך לראות מה אפשרי. (למידע על ההתקדמות בבינה מלאכותית, ראה האם מחשבים מסוגלים לחקות את המוח האנושי?)
סגנון עצבי
אתה לא יכול לשפר את כישורי התכנות שלך כאשר לאף אחד לא אכפת מאיכות התוכנה.
מספר סיפורים עצבי

מספר סיפורים עצביים הוא מודל שכאשר ניתן לו תמונה, יכול ליצור סיפור רומנטי על הדימוי. זה צעצוע מהנה ובכל זאת אתה יכול לדמיין את העתיד ולראות את הכיוון אליו עוברים כל דגמי הבינה המלאכותית.

הפונקציה לעיל היא פעולת "הסטת הסטייל" המאפשרת לדגם להעביר כותרות תמונה סטנדרטיות לסגנון סיפורים מרומנים. הסטת סגנון נוצרה בהשראת "אלגוריתם עצבי של סגנון אמנותי."
נתונים
ישנם שני מקורות נתונים עיקריים המשמשים במודל זה. MSCOCO הוא מערך נתונים ממיקרוסופט המכיל כ -300,000 תמונות, כאשר כל תמונה מכילה חמש כותרות. MSCOCO הוא הנתונים המפוקחים היחידים בהם נעשה שימוש, כלומר הם הנתונים היחידים שבהם בני אדם נאלצו להיכנס ולכתוב במפורש כיתובים לכל תמונה.
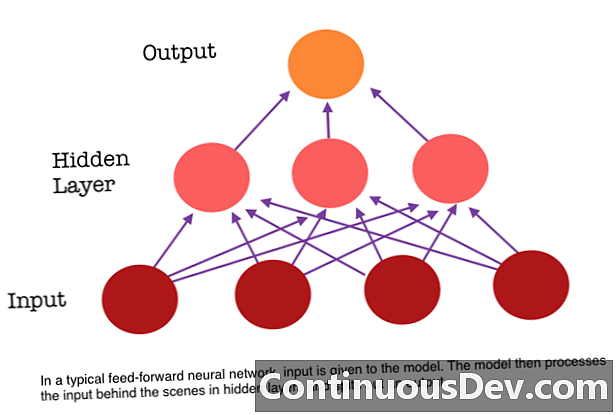
אחת המגבלות העיקריות של רשת עצבית קדימה היא שאין לה זיכרון. כל תחזית אינה תלויה בחישובים קודמים, כאילו הייתה התחזית הראשונה והיחידה שהרשת ביצעה אי פעם. אך עבור משימות רבות, כגון תרגום משפט או פסקה, התשומות צריכות להיות מורכבות מנתונים רציפים וקשורים זה לזה. לדוגמה, יהיה קשה להבין את המילה היחידה במשפט ללא המילים המסופקות על ידי המילים שמסביב.
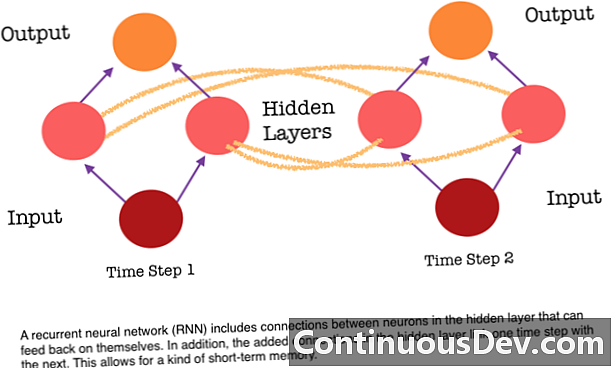
RNNs הם שונים מכיוון שהם מוסיפים קבוצה נוספת של קשרים בין נוירונים. קישורים אלה מאפשרים להפעלה מהנוירונים בשכבה נסתרת להיכנס לעצמם בשלב הבא ברצף. במילים אחרות, בכל שלב, שכבה נסתרת מקבלת גם הפעלה מהשכבה שמתחתיה וגם מהצעד הקודם ברצף. מבנה זה מעניק למעשה זיכרון רשתות עצביות חוזרות. אז לצורך משימת איתור האובייקטים, RNN יכול לנצל את הסיווגים הקודמים שלו של כלבים כדי לעזור לקבוע אם התמונה הנוכחית היא כלב.
Char-RNN TED
מבנה גמיש זה בשכבה המוסתרת מאפשר ל- RNN להיות טוב מאוד למודלים בשפה ברמת הדמות. Char RNN, שנוצר במקור על ידי אנדרהj Karpathy, הוא מודל שלוקח קובץ אחד כקלט ומאמן RNN ללמוד לחזות את הדמות הבאה ברצף. ה- RNN יכול ליצור תו אחר תו שייראה כמו נתוני האימונים המקוריים. הדגמה הוכשרה באמצעות תמלילים של שיחות TED שונות. הזן את הדגם מילת מפתח אחת או כמה והיא תייצר קטע אודות מילות המפתח בקול / סגנון של TED Talk.
סיכום
דגמים אלה מראים פריצות דרך חדשות באינטליגנציה מכונה שהפכה אפשרית בגלל למידה עמוקה. למידה מעמיקה מראה שאנו יכולים לפתור בעיות שלעולם לא יכולנו לפתור קודם, ועדיין לא הגענו לרמה ההיא. צפו לראות דברים רבים ומרתקים יותר כמו מכוניות נטולות נהגים במהלך השנים הקרובות, כתוצאה מחדשנות למידה עמוקה.